The “internet”, as the name implies, is a network of networks. Scuttleblurb.com is sitting on server somewhere connected to an IP network different from the one your device is connected to and the fact that you are reading this means those two networks are communicating. Likewise, if your internet service provider is Charter and you’d like to send an email to a friend whose ISP is Comcast, the networks of Charter and Comcast need a way to trade data traffic (“peer” with one another). In the nascent days of the internet, different networks did this at Network Access Points established and operated by non-profits and the government. Over time, large telecom carriers, who owned the core networks, took control of coordinating peering activity and small carriers that wished to exchange traffic with them were forced to house switching equipment on their premises.
Eventually, most peering agreements moved to “carrier-neutral” Internet Exchange Points (“IXs” or “IXPs”, data centers like those owned and/or operated by Equinix and Interxion) that were independent of any single carrier. Today, global carrier neutral colocation/interconnection revenue of $15bn exceeds that of bandwidth provider colo by a factor of two as major telcos have seen their exchange businesses wither. At first, service providers landed hooks at these neutral exchange points…and then came the content providers, financial institutions, and enterprises, in that order. Customers at these neutral exchange points can connect to a single port and access hundreds of carriers and ISPs within a single data center or cluster of data centers. Alternatively, a B2B enterprise that wants to sync to its partners and customers without enduring the congestion of public peering [on a “shared fabric” or “peering fabric”, where multiple parties interconnect their networks at a single port] can establish private “cross-connects”, or cables that directly tether its equipment to that of its customers within the same DC [in an intracampus cross connect, the DC operator connects multiple datacenters with fiber optic cables, giving customers access to customers located in other DC buildings].
[To get a sense of how consequential network peering is to experiencing the web as we know it today, here’s an account of a de-peering incident, as told by Andrew Blum in his book Tubes: Behind the Scenes at the Internet:
“In one famous de-peering episode in 2008, Sprint stopped peering with Cogent for three days. As a result, 3.3% of global Internet addresses ‘partitioned’, meaning they were cut off from the rest of the Internet…Any network that was ‘single-homed’ behind Sprint or Cogent – meaning they relied on the network exclusively to get to the rest of the Internet – was unable to reach any network that was ‘single-homed’ behind the other. Among the better-known ‘captives’ behind Sprint were the US Department of Justice, the Commonwealth of Massachusetts, and Northrop Grumman; behind Cogent were NASA, ING Canada, and the New York court system. Emails between the two camps couldn’t be delivered. Their websites appeared to be unavailable, the connection unable to be established.”]
The benefits of colocation seem obvious enough. Even the $2mn+ of capital you’re laying out upfront for a small 10k sf private build [1]is a pittance compared to the recurring expenses – taxes, staff, and maintenance, and especially power – of operating it. You won’t get the latency benefits of cross-connecting with customers, you’ll pay costly networking tolls to local transit providers, and you’re probably not even going to be using all that built capacity most of the time anyhow.
There’s this theory in urban economics called “economies of agglomeration”, which posits that firms in related industries achieve scale economies by clustering together in a confined region, as the concentration of related companies attracts deep, specialized pools of labor and suppliers that can be accessed more cost effectively when they are together in one place, and results in technology and knowledge spillovers. For instance, the dense concentration of asset managers in Manhattan attracts newly minted MBAs looking for jobs, service providers scouring for clients, and management teams pitching debt and equity offerings. Analysts at these shops can easily and informally get together and share ideas. This set of knowledge and resources, in turn, compels asset managers to set up shop in Manhattan, reinforcing the feedback loop.
I think you see where I’m going with this. The day-to-day interactions that a business used to have with its suppliers, partners, and customers in physical space – trading securities, coordinating product development, placing an order, paying the bills – have been increasingly mapped onto a virtual landscape over the last several decades. Datacenters are the new cities. Equinix’s critical competitive advantage, what separates it from being a commodity lessor of power and space, resides in the network effects spawned by connectivity among a dense and diverse tenant base within its 180+ data centers. You might also cite the time and cost of permitting and constructing a datacenter as an entry barrier, and this might be a more valid one in Europe than in the US, but I think it’s largely besides the point. The real moat comes from convincing carriers to plug into your datacenter and spinning up an ecosystem of connecting networks on top.
The roots of this moat extend all the back to the late ’90s, when major telecom carriers embedded their network backbones into datacenters owned by Interxion, Telx [acquired by Digital Realty in October 2015], and Equinix, creating the conditions for network effects to blossom over the ensuing decade+: a customer will choose the interconnection exchange on which it can peer with many other relevant customers, partners, and service providers; carriers and service providers, in virtuous fashion, will connect to the exchange that supports a critical mass of content providers and enterprises. Furthermore, each incremental datacenter that Equinix or Interxion builds is both strengthened by and reinforces the existing web of connected participants in current datacenters on campus, creating what are known as “communities of interest” among related companies, like this (from Interxion):

[The bottom layer, the connectivity providers, used to comprise ~80% of INXN’s revenue in the early 2000s]
So, for instance, and I’m just making this up, inside an Interxion datacenter, Netflix can manage part of its content library and track user engagement by cross-connecting with AWS, and distribute that content with a high degree of reliability across Europe by syncing with any number of connectivity providers in the bottom layer. In major European financial centers, where Interxion’s datacenter campuses host financial services constituents, a broker who requires no/low latency trade execution and data feeds can, at little or no cost, cross-connect with trading venues and providers of market data who are located on the same Interxion campuses. Or consider all the parties involved in an electronic payments transaction, from processors to banks to application providers to wireless carriers, who must all trade traffic in real time. These ecosystems of mutually reinforcing entities have been fostered over nearly 20 years and are difficult to replicate. Customers rely on these datacenters for mission critical network access, making them very sticky, as is evidenced by Equnix’s MRR churn rate of ~2%-2.5%.
[Here’s a cool visual from Equinix’s Analyst Day that shows how dramatically its Chicago metro’s cross-connects have proliferated over the last 6 years, testifying to the network effects at play. Note how thick the fibers on the “Network” cell wall are. Connectivity providers are the key.]
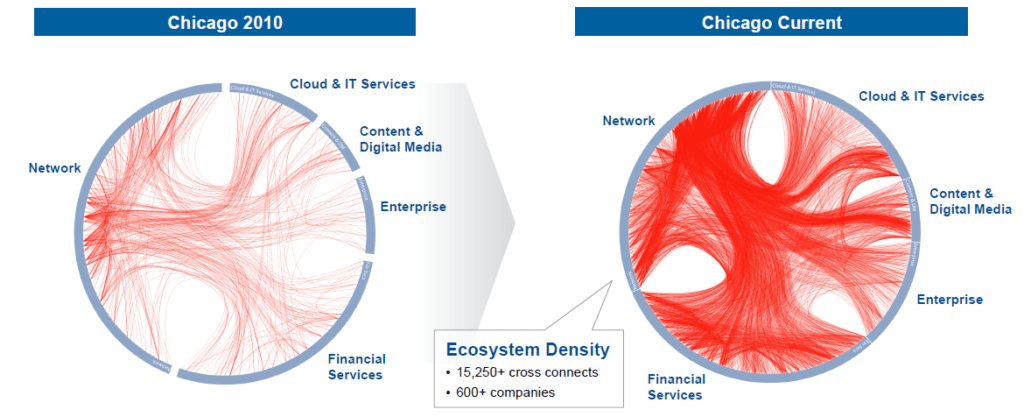
The carrier-rich retail colocation datacenters that I refer to in this post differ from their more commodified “wholesale” cousins in that the latter cater to large enterprises that lease entire facilities, design and construct their architectures, and employ their own technical support staff. Retail datacenters with internet exchanges, meanwhile, are occupied by smaller customers who lease by the cabinet, share pre-configured space with other customers, and rely on the DC’s staff for tech support. But most critically, because wholesale customers primarily use DCs for space and power rather than connectivity, they do not benefit from the same network effects that underpin the connectivity-rich colo moat. It is the aggregation function that gives rise to a fragmented customer base of enterprises, cloud and internet service providers, and system integrators (Equinix’s largest customer accounts for less than 3% of monthly recurring revenue) and allows the IX colo to persistently implement price hikes that at least keep up with inflation.
This is not the case for a wholesale DC provider, who relies on a few large enterprises that wield negotiating leverage over them. DuPont Fabros’ largest customer is over 25% of revenue; it’s second largest accounts for another 20%. A simple way to see the value differentiation between commodity wholesale and carrier-rich retail data center operators is to simply compare their returns on gross PP&E over time.
| EBITDA / BoP Gross PPE | |
| Avg | |
| 2011-2016 | |
| Wholesale | |
| DuPont Fabros | 9.0% |
| Digital Realty | 10.1% |
| IX Retail | |
| Equinix | 16.7% |
| Interxion | 15.1% |
[There are also retail colos without internet exchange points that deliver more value for their customers than wholesale DCs but less compared to their IX retail brethren, and some DCs operate a hybrid wholesale/retail model as well. It’s a spectrum]
So you can see why wholesale DCs have been trying to break into the IX gambit organically, with little success, for years. Digital Realty, which today gets ~15% of its revenue from interconnection, bought its way into the space through its acquisition of Telx in October 2015, followed up by its acquisition of a portfolio of DCs from Equinix in July 2016. The secular demand drivers are many…I’m talking about all the trends that have been tirelessly discussed for the last several years: enterprise cloud computing, edge computing, mobile data, internet of things, e-commerce, streaming video content, big data. These phenomena are only moving in one direction. We all know this and agree.
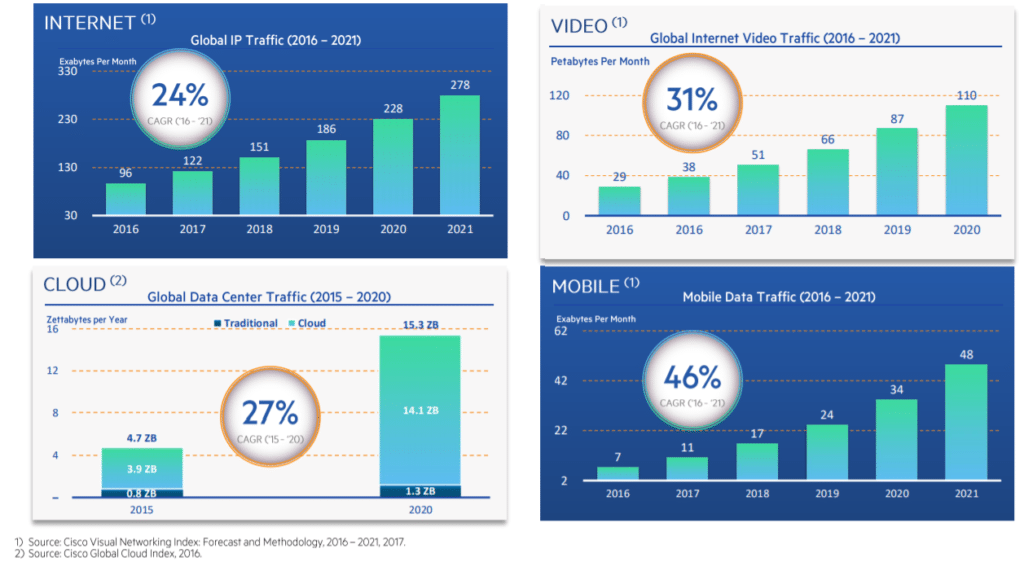
But it’s not just about the amount of data that is generated and consumed, but also about how. The ever hastening pace and competitiveness of business demand that companies have access to applications on whatever device wherever they happen to be; the data generated from their consumption patterns and from the burgeoning thicket of IoT devices need to, in turn, be shot back to data center nodes for analysis and insight. And the transfer of data to and from end users and devices to the datacenters needs to happen quickly and cheaply. Today, the typical network topology looks something like this…
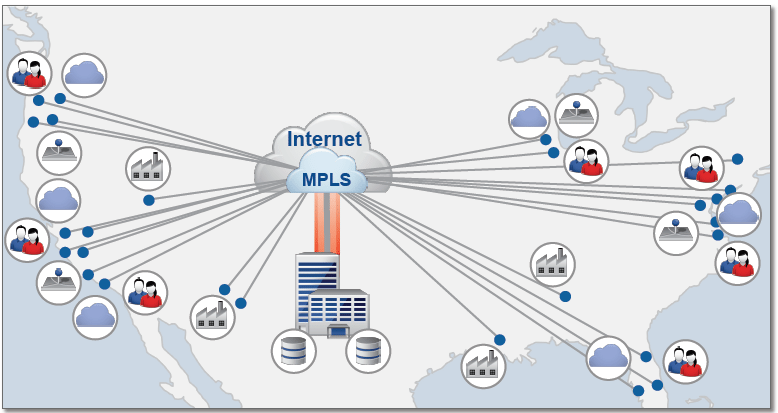
…a hub-and-spoke model where an application traverses great lengths from a core datacenter located somewhere in the sticks to reach end users and data is then backhauled from the end user back to the core. This is expensive, bandwidth-taxing, slow, and because it is pushed over the public internet, sometimes in technical violation of strict security and privacy protocols. You can imagine how much data a sensor-laden self-driving car generates every minute and how unacceptably long it would take and how expensive it would be to continuously transfer it all back to the core over a 4G network. Instead, the IT network should be reconfigured to instead look like this…
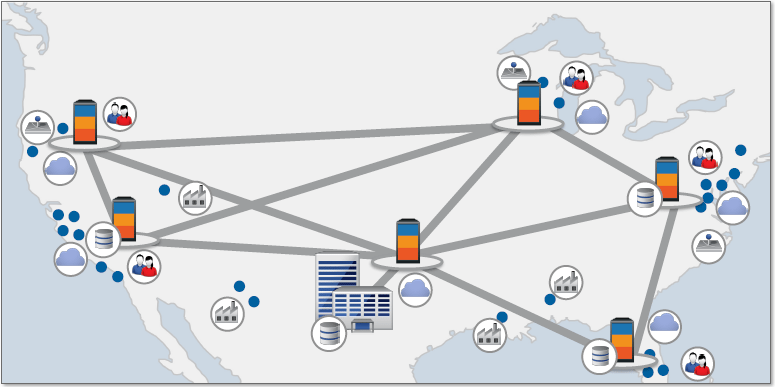
…a widely-distributed footprint of nodes close to end user/device, each node hosting a rich ecosystem of networks and cloud partners that other networks and cloud partners care about, pushing and pulling bits to and from users more securely and with far less latency vs. the hub/spoke configuration. Microsoft clearly shares the same vision. Satya Nadella on MSFT’s fiscal 4q conference call:
“So to me that’s what we are building to. It’s actually a big architectural shift from thinking purely of this as a migration to some public cloud to really thinking of this as a real future distributed computing infrastructure and applications…from a forward looking perspective I want us to be very, very clear that we anticipate the edge to be actually one of the more exciting parts of what’s happening with our infrastructure.”
Something to consider is that while distributed computing appears to offer tailwind for the IX colos, it can have existential whiffs when pushed to the extreme. Is it really the long-term secular trend that EQIX management unequivocally proclaims it to be? Or is it just a processing pit stop for workloads that are inexorably inching their way further to the edge, to be directly manipulated by increasingly intelligent devices?
Consider that this past summer, Microsoft released Azure IoT Edge, a Windows/Linux solution that enables in-device AI and analytics using the same code running in the cloud. To draw an example from Microsoft’s Build Developer conference, Sandvik Coromant, a Swedish manufacturer of cutting tools, already has machines on its factory floors that send telemetry to the Azure cloud, where machine learning is applied to the data to predict maintenance needs and trigger preemptive machine shutdowns when certain parameters are tripped. But with Azure IoT Edge, that logic, and a whole menu of others that used to reside solely in the cloud, can now be ported directly to the machines themselves. The process loop – sending telemetry from the device to the cloud, analyzing it, and shooting it back down to the device – is obviated, cutting the time to decommission a faulty machine from 2 seconds down to ~100 milliseconds. While this seems like the cloud node is rendered inert, note that the algorithms are still developed and tested in the data center before being exported to and executed on the device…and even as in-device local AI becomes more sophisticated, the data deluge from burgeoning end nodes will still need to be synced to a centralized processing repository to more intensively train machine learning algorithms and generate predictive insights that are more expansive than can be derived locally.
But there is also the fear that as enterprises consider moving workloads off-premise, they bypass hybrid [public + private colocated or on-premise cloud services] and host mostly or entirely with a public hyperscale vendor (AWS, Azure, Google Cloud) [a colocated enterprise brings and maintains its own equipment to the datacenter, whereas a public cloud customer uses the equipment of the cloud provider] or that current hybrid enterprises migrate more and more workloads to the public cloud…or that public cloud vendors build out their own network nodes to host hybrid enterprises. But by all accounts, Equinix is in deep, mutually beneficial partnership with Cloud & IT services customers (AWS, Google, Azure, Box, SaaS companies), who have been the most significant contributors to Equinix’s monthly recurring revenue (MRR) growth over the last several years. The hyperscalers are relying on connectivity-rich colos like Equinix and Interxion to serve as their network nodes to meet latency needs on the edge.
There are 50 or so undersea cable initiatives in the world today that are being constructed to meet the proliferating amount of cross-border internet traffic, which has grown by 45x over the last decade. These subsea projects are being funded not by telecom networks as in days past, but by the major public cloud vendors and Facebook, who are landing many of those cables directly on third party interconnection-rich colos that host their web services.

[Source: TeleGeography]
Cloud & IT customers comprise half the Equinix’s top 10 customers by monthly recurring revenue (MRR), operate across all three of the company’s regions (America, EMEA, and APAC) in, on average, 40 of its datacenters [compared to 4 of the top 10 operating in fewer than 30 datacenters, on average, just a year ago]. The number of customers and deployments on Equinix’s Performance Hub, where enterprises can cross-connect to the public clouds and operate their private cloud in hybrid fashion, has grown by 2x-3x since 1q15, while 50%+ growth in cross-connects to cloud services has underpinned 20% and 14% recurring revenue CAGRs for Enteprise and Cloud customers, respectively, over the last 3 years.
Still another possible risk factor was trumpeted with great fanfare during CNBC’s Delivering Alpha conference last month by Social Capital’s Chamath Palihapitiya, who claimed that Google was developing a chip that could run half of its computing on 10% of the silicon, leading him to conclude that: “We can literally take a rack of servers that can basically replace seven or eight data centers and park it, drive it in an RV and park it beside a data center. Plug it into some air conditioning and power and it will take those data centers out of business.”
While this sounds like your standard casually provocative and contrived sound-bite from yet another SV thought leader, it was taken seriously enough to spark a sell-off in data center stocks and put the management teams of those companies on defense, with Digital Realty’s head of IR remarking to Data Center Knowledge:
“Andy Power and I are in New York, meeting with our largest institutional investors, and this topic has come up as basically the first question every single meeting.”
To state the obvious, when evaluating an existential claim that is predicated upon extrapolating a current trend, it’s often worth asking whether there is evidence of said trend’s impact today. For instance, the assertion that “intensifying e-commerce adoption will drive huge swaths of malls into extinction”, while bold, is at least hinted at by moribund foot traffic at malls and negative comps at mall-based specialty retailers over the last several years. Similarly, if it is indeed true that greater chip processing efficiency will dramatically reduce data center tenancy, it seems we should already be seeing this in the data, as Moore’s law has reliably held since it was first articulated in the 1970s, and server chips are far denser and more powerful today than they were 5-10 years ago. And yet, we see just the opposite.
Facebook, Microsoft, Alphabet, and Amazon are all accelerating their investments in datacenters in the coming years – opening new ones, expanding existing ones – and entering into long-term lease agreements with both wholesale and connectivity colo datacenter operators. Even as colocation operators have poured substantial sums into growth capex, utilization rates have trekked higher. Unit sales of Intel’s datacenter chips have increased by high-single digits per year over the last several years, suggesting that the neural networking chips that CP referred to are working alongside CPU servers, not replacing them.
It seems a core assumption to CP’s argument is that the amount of data generated and consumed is invariant to efficiency gains in computing. But cases to the contrary – where efficiency gains, in reducing the cost of consumption, have actually spurred more consumption and nullified the energy savings – are prevalent enough in the history of technological progress that they go by a name, “Jevons paradox”, described in this The New Yorker article from December 2010 [2]:
In a paper published in 1998, the Yale economist William D. Nordhaus estimated the cost of lighting throughout human history. An ancient Babylonian, he calculated, needed to work more than forty-one hours to acquire enough lamp oil to provide a thousand lumen-hours of light—the equivalent of a seventy-five-watt incandescent bulb burning for about an hour. Thirty-five hundred years later, a contemporary of Thomas Jefferson’s could buy the same amount of illumination, in the form of tallow candles, by working for about five hours and twenty minutes. By 1992, an average American, with access to compact fluorescents, could do the same in less than half a second. Increasing the energy efficiency of illumination is nothing new; improved lighting has been “a lunch you’re paid to eat” ever since humans upgraded from cave fires (fifty-eight hours of labor for our early Stone Age ancestors). Yet our efficiency gains haven’t reduced the energy we expend on illumination or shrunk our energy consumption over all. On the contrary, we now generate light so extravagantly that darkness itself is spoken of as an endangered natural resource.
Modern air-conditioners, like modern refrigerators, are vastly more energy efficient than their mid-twentieth-century predecessors—in both cases, partly because of tighter standards established by the Department of Energy. But that efficiency has driven down their cost of operation, and manufacturing efficiencies and market growth have driven down the cost of production, to such an extent that the ownership percentage of 1960 has now flipped: by 2005, according to the Energy Information Administration, eighty-four per cent of all U.S. homes had air-conditioning, and most of it was central. Stan Cox, who is the author of the recent book “Losing Our Cool,” told me that, between 1993 and 2005, “the energy efficiency of residential air-conditioning equipment improved twenty-eight per cent, but energy consumption for A.C. by the average air-conditioned household rose thirty-seven per cent.”
And the “paradox” certainly seems apparent in the case of server capacity and processing speed, where advances have continuously accommodated ever growing use cases that have sparked growth in overall power consumption. It’s true that GPUs are far more energy efficient to run than CPUs on a per instruction basis, but these chips are enabling far more incremental workloads than were possible before, not simply usurping a fixed quantum of work that was previously being handled by CPUs.
With all this talk around chip speed, it’s easy to forget that the core value proposition offered by connectivity-rich colos like EQIX and INXN is not processing power but rather seamless connectivity to a variety of relevant networks, service providers, customers, and partners in a securely monitored facility with unimpeachable reliability. When you walk into an Equinix datacenter, you don’t see infinity rooms of servers training machine learning algorithms and hosting streaming sites, but rather cabinets housing huge pieces of switching equipment syncing different networks, and overhead cable trays secured to the ceiling, shielding thousands of different cross-connects.
The importance of connectivity means that the number of connectivity-rich datacenters will trend towards but never converge to a number that optimizes for scale economies alone. A distributed topology with multiple datacenter per region, as discussed in this post and outlined in this article [3], addresses several problems, including the huge left tail consequences of a single point of failure, the exorbitant cost of interconnect in regions with inefficient last-mile networks, latency, and jurisdictional mandates, especially in Europe, that require local data to remain within geographic borders. Faster chips do not solve any of these problems.
Incremental returns
An IX data center operator leases property for 10+ years and enters into 3-5 year contracts embedded with 2%-5% price escalators with customers who pay monthly fees for rent, power, and interconnection fees that comprise ~95% of total revenue. A typical new build can get to be ~80% utilized within 2-5 years and cash flow breakeven inside of 12 months. During the first two years or so after a datacenter opens, the vast majority of recurring revenue comes from rent. But as the datacenter fills up with customers and those customers drag more and more of their workloads to the colo and connect with other customers within the same datacenter and across datacenters on the same campus, power and cross-connects represent an ever growing mix of revenue such that in 4-5 years time, they come to comprise the majority of revenue per colo and user.
The cash costs at an Equinix datacenter break down like this:
% of cash operating costs at the datacenter:
Utilities: 35%
Labor: 19%
Rent: 15%
Repairs/Maintenance: 8%
Other: 23%
So, roughly half of the costs – labor, rent, repairs, ~half of “other” – are fixed.
If you include the cash operating costs below the gross profit line [cost of revenue basically represents costs at the datacenter level: rental payments, electricity and bandwidth costs, IBX data center employee salaries (including stock comp), repairs, maintenance, security services.], the consolidated cost structure breaks down like this:
% of cash operating costs of EQIX / % of revenue / mostly fixed or variable in the short-term?
Labor: 40% / 23% / fixed (including stock-based comp)
Power: 20% / 11% / variable
Consumables & other: 19% / 10% / semi-fixed
Rent: 8% / 5% / fixed
Outside services: 7% / 4% / semi-fixed
Maintenance: 6% / 3% / fixed
With ~2/3 of EQIX’s cost structure practically fixed, there’s meaningful operating leverage as datacenters fill up and bustle with activity. Among Equinix’s 150 IBX datacenters (that is, datacenters with ecosystems of businesses, networks, and service providers), 99 are “stabilized” assets that began operating before 1/1/2016 and are 83% leased up. There is $5.7bn in gross PP&E tied up in those datacenters which are generating $1.6bn in cash profit after datacenter level stock comp and maintenance capex (~4% of revenue), translating into a 28% pre-tax unlevered return on capital.
Equinix is by far the largest player in an increasingly consolidated industry. It got that way through a fairly even combination of growth capex and M&A. The commercial logic to mergers in this space comes not just from cross-selling IX space across a non-overlapping customer base and taking out redundant SG&A, but also in fusing the ecosystems of datacenters located within the same campus or metro, further reinforcing network effects. For instance, through its acquisition Telecity, Equinix got a bunch of datacenters that were adjacent to its own within Paris, London, Amsterdam, and Frankfurt. By linking communities across datacenters within the same metros, Equinix is driving greater utilization across the metro as a whole.
While Equinix’s 14% share of the global retail colo + IX market is greater than 2x its next closest peer, if you isolate interconnection colo (the good stuff), the company’s global share is more like 60%-70%. Furthermore, according to management, half of the next six largest players in below chart are looking to divest their colocation assets, and of the remaining three, two serve a single region and one is mostly a wholesale.
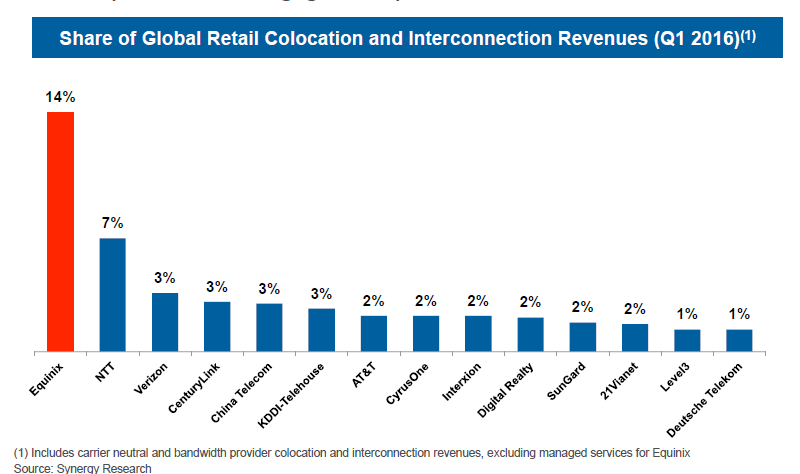
Equinix points to its global footprint as a key competitive advantage, but it’s important to qualify this claim, as too many companies casually and erroneously point to their “global” presence as a moat. By being spread across multiple continents, you can leverage overhead cost somewhat, offer multi-region bundled pricing to customers, and point to your bigness and brand during the sales process. Equinix claims that around 85% of its customers reside in multiple metros and 58% in all three regions (Americas, EMEA, APAC)…but a lot of these multi-region relationships were simply manufactured through acquisition and in any case, the presence of one customer in multiple datacenters doesn’t really answer the question that really matters, which is this: does having a connectivity-rich colo in, say, New York City make it more likely that a customer will choose your colo in, say, Paris (and vice-versa) over a peer who is regionally better positioned and has a superior ecosystem? I don’t see why it would. I’m not saying that a global presence is irrelevant, just that housing the customer in one region does not make him inherently captive to you in another. A customer’s choice of datacenter will primarily be dictated by regional location, connectivity, ecosystem density, and of course, reliability and security.
Which is why I wouldn’t be so quick to conclude that Equinix, by virtue of its global girth, wields an inherent advantage over Interxion, another fine connecity-rich that gets all its revenue from Europe. Over the years, INXN has been a popular “play” among eventy types hoping for either a multiple re-rating on a potential REIT conversion or thinking that, as a $3.6bn market cap peon next to an acquisitive $36bn EQIX, the company could get bought. But the company has its fundamental, standalone charms too.
The European colos appear to have learned their lesson from being burned by overexpansion in the early 2000s, and have been careful to let demand drive high-single digit supply growth over the last decade. As tirelessly expounded in this post, replicating a carrier rich colo from scratch is a near insuperable feat, attesting to why there have been no new significant organic entrants in the pan-European IX data center market for the last 15 years and why customers are incredibly sticky even in the face of persistent price hikes. European colos are also riding the same secular tailwinds propelling the US market – low latency and high connectivity requirements by B2B cloud and content platforms – though with a ~1-2 year lag.
The combination of favorable supply/demand balance, strong barriers to entry, and a secularly growing demand drivers =
The near entirety of INXN’s growth has been organic too.
Compared to Equinix, Interxion earns somewhat lower returns on gross capital on mature data centers, low-20s vs. ~30%. I suspect that part of this could be due to the fact that Interxion does not directly benefit from high margin interconnection revenues to the same degree as Equinix. Interconnect only constitutes 8% of EQIX’s recurring revenue in EMEA vs. nearly 25% in the US. And cross-connecting in Europe has historically been free or available for a one time fee collected by the colo (although this service is transitioning towards a recurring monthly payment model, which is the status quo in the US).
[INXN has invested over €1bn in infrastructure, land, and equipment to build out the 34 fully data centers it operated at the start of 2016. Today, with 82% of 900k+ square feet utilized, these data centers generate nearly ~€370mn in revenue and ~€240mn in discretionary cash flow [gross profit less maintenance capex] to the company, a 23% annual pre-tax cash return on investment [up from mid-teens 4 years ago] that will improve further as recurring revenue accretes by high-single digits annually on price increases, capacity utilization, cross-connects, and power consumption.]
But in any case, the returns on incremental datacenter investment are certainly lofty enough to want to avoid the dividend drain that would attend REIT conversion. Why convert when you can take all your operating cash flow, add a dollop of leverage, and invest it all in projects earning 20%+ returns at scale? As management recently put it:
“…the idea of sort of being more tactical and as you described sort of let – taking some of that capital and paying a little bit of dividend, to me, that doesn’t smack of actually securing long-term, sustainable shareholder returns.”
Equinix, on the other hand, must at a minimum pay out ~half its AFFO in dividends, constraining the company’s organic capacity to reinvest, forcing it to persistently issuing debt and stock to fund growth capex and M&A. Not that EQIX’s operating model – reinvesting half its AFFO, responsibly levering up, earning ~30% incremental returns, and delevering over time – has shareholders hurting.
[AFFO = Adj. EBITDA – stock comp – MCX – taxes – interest]
And there’s still a pretty long runway ahead, for both companies. Today’s retail colocation and interconnection TAM is around $23bn, split between carrier neutral colos at ~$15bn and bandwidth providers at ~$8bn, the latter growing by ~2%, the former by ~8%. Equinix’s prediction is that the 8% growth will be juiced a few points by enterprises increasingly adopting hybrid clouds, so call it 10% organic revenue growth, which would be slower than either company has registered the last 5 years. Layer in the operating leverage and we’re probably talking about low/mid-teens maintenance free cash flow growth.
At 28x AFFO/mFCFE, EQIX and INXN are not statistically cheap stocks. But it’s no so easy to find companies protected by formidable moats with credible opportunities to reinvest capital at 20%-30% returns for many years. By comparison, a deep-moater like VRSK [4] is trading at over 30x free cash flow, growing top-line by mid/high single digits, and reinvesting nearly all its prodigious incremental cash flow in share buybacks and gems like Wood Mac and Argus that are unlikely to earn anywhere near those returns.
Notes
INXN claims to be the largest pan-European player in the market, which is technically true but also a bit misleading because in the big 4 European markets (France, Germany, Netherlands, and the UK) that constitute 65% of its business, by my estimate, Interxion still generates less than 1/3 the revenue of Equinix. Even before the Telecity acquisition in January 2016, EQIX generated more EMEA revenue than Interxion, but now it has more datacenters and across more countries in the region too [well, depending on how you define “region” as the set of countries covered in Equinix’s EMEA is more expansive than that covered by Interxion].